经常使用spark提交任务,但是很少关注partition的概念,虽然经常设置executor的个数,executor_memory,executor-core等值,但是没有关注partition的概念,使用textFile处理文本log也是采用的默认partition设置,今天对partiton的概念稍微理一理。
tensorflow tutorial -分布式tf
分布式tf
准备tf.train.ClusterSpec 用来映射task到机器。
当通过tf.train.Server.create_local_server()时候,会返回如图log信息供参考
1 | >> server = tf.train.Server.create_local_server() |
查看server以及对应的targe信息
1 | >> print server.target |
data parallelism ,worker has same model with different batch size data
图内复制
in-graph replication
between-graph replication
图间复制
TensorFlowOnSpark
Yahoo!开源的TFoS,集中tf以及spark,tfos支持GPU/CPU集群上的分布式深度学习。
支持spark上的training、支持inference。通过如下步骤管理tf
a、在executor上launch tf,同时监听数据/控制流信息。
b、数据读取方式有两种:Reader和QueueRunner,QueueRunner是 tf提供数据读取接口
leverage tf的reader接口从hdfs上直接读取数据;使用feed_dict机制,将RDD发送到feed_dict上。
tensorflow tutorial -神经网络模型
从SimpleNeuralNetwork开始构建多层感知机到CNN再到LSTM,通过代码熟悉tf下DNN的模型构建方式。
构建一个包含2个隐含层hidden layers全连接网络,也即平常说的多层感知机multi layer perceptron,继续使用mnist数据集进行模型训练以及应用。
这里设置2层,每层256个神经节点neurons,输入为784dim的image,output为10 classes。
对于中间的hidden layer,需要的w为
1 | num_input = 784 |
tensorflow tutorial-入门
背景
在搜索tensorflow(TF)相关的资料时候,发现在github上有比较多的example,其实在学习其他新内容,总是会有类似effectiveC++,efftiveGo,effectiveScala等类似总结,尝试搜了下effectiveTensorflow,发现这里还是有一个可以参考
同时还有一个star较高的examples作为学习的tutorial,地址在这里
本文打算从example这里开始,打算以此作为基础,先将tf相关的所有api尽可能熟悉,然后基于effective系列来了解常规的code style,最后再深入tf的基础架构、设计原理去深层次的了解。
使用travis自动构建blog
背景
在使用travis构建blog之前,对travis并没有系统的使用过,也仅仅停留在听过这个产品,听过其用途,随着总结欲望的增加,发现在跨多个机器上写blog的时候,总是需要安装hexo,这些环境通过github来作为中间者进行同步,时间长了,会逐渐忘记hexo的部署命令以及本机的部署环境,写blog的目录等,在往往在随着这些琐碎的事情的增加,而逐渐减少了写blog的欲望。
最近看到travis进行blog的自动构建,发现可以很大程度上减少对部署环境的依赖,而只要聚焦在写blog上即可。因此折腾了一个下午,将travis接入自己的blog构建,本篇文章记录了这个折腾的过程,同时也记录一些自己目前还没有解决掉的问题,期望后面会逐渐优化这个过程。
使用hexo构建支持latex的blog
背景
之前使用了jekyll构建静态blog,但是在公式配置上一直没有配置合理,导致文章中的公式显示经常出现问题。结果反而让自己变的更懒而不勤于书写文章。偶然间看到hexo这个东东更加方便,并且起NexT主题中默认支持mathjax,不用自己再设置各种plugin来支持(事实上没有使用NexT theme之前,也设置了好久来支持公式,但是无果)。
因此打算将第一篇文章来描述如何使用hexo。
点击率预估算法survey之FTRL
论文主要内容
参考的paper是
在LR算法训练中,在第t个instance上的logloss为
$logloss_t(w_t) = -y_tlog p_t - (1-y_t)log(1-p_t)$
其中$w_t$是训练当前这轮的权重,$y_t$是label,$p_t$是预估的结果,即sigmoid函数的计算结果。一般$y_t$是0或者1。因此这个公式可以简化为
$$ logloss_t(w_t)= \begin{cases} -log(1-p_t), & \text {if $y_t=0$} \ -logp_t, & \text{if $y_t=1$} \end{cases} $$
从而推倒出的gradient为
$g = (p_t-y_t)x_t$,而instance在预处理之后对应的$x_t$一般是libsvm的数据格式,即$featid:1$,所以$x_t$的值一般是1,因此这里可以等价为$g = p_t-y_t$。
基于libev的网络服务框架
背景
目前参与的几个后台服务都是基于libev构建的异步网络服务框架,我们将libev进行了简单的封装形成了Reactor类,并形成了自己稳定的异步服务框架,这里 针对当前网络服务框架进行剖析,以期望未来可以轻松的使用这个框架构建任意的高并发、稳定的后台服务。
machine learning tutorial summary
背景
auc的可行性计算
理论上,基于(fpr,tpr)对图形进行累积可以计算出auc,但是需要进行累加矩形面积,略显啰嗦。实际中可以采用更易计算的公式直接推导即可。一个常用的计算公式如下图所示
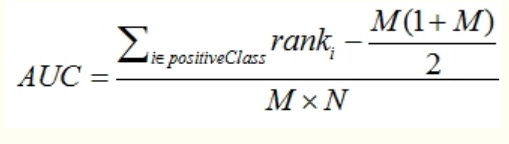
其中M是正样本,N是负样本个数。